

GPTs can reach AGI, and here's how
GPTs can reach AGI, and here's how
This is not a Bing freak-out post. Large Language Models can reach human-level general intelligence via in-session training.
Large Language Models and where to find them
LLMs, like ChatGPT, learned English grammar while it was trained to make next-word predictions. The vanilla ChatGPT/LLM, therefore, emulates the speech pattern of the most generic human. To make sure ChatGPT does not spill out any racial slurs or curses (as a generic person could), OpenAI fine-tuned it with Reinforcement Learning with Human Feedback (RLHF). Basically, a human rater rewards the LLM when it provides a satisfactory response and punishes it when it spits out hateful curses. Gradually, ChatGPT became better at providing satisfactory responses to humans. Through RLHF, an LLM learns facades of our linguistic politeness and moral values. It learns to emulate a “Helpful, Harmless, and Honest” agent to satisfy the human user with its responses. Scott Alexander wrote a blog comparing the way an LLM learns to emulate an “HHH” agent to the ways infants learn to obey social norms. And he concluded that LLMs are more similar to humans than we had thought before. This gives an LLM the potential to become a real “agent” like us.
I am actually not too concerned that this similarity would enable LLMs to become AGI agents. I am more unsettled by the prospect of another mode of training that could readily turn LLMs into AGI agents: in-session training.
An LLM can do in-session learning
An LLM’s life cycle is divided into two stages: “training” and “deployment.” When the LLM is being trained to make next-word predictions and finetuned by RLHF, we say that the LLM is in the “training” stage. But once OpenAI published ChatGPT onto the web, and allowed ChatGPT to interact with human users, ChatGPT entered the “deployment” stage.
In reality, the separation between “training” and “deployment” is not absolute. During each session of “deployment,” the LLM continues to learn how best to satisfy its user. Since RLHF gave the chatbot the goal of providing satisfactory answers to humans, the chatbot would continue to learn and adapt itself to the user’s needs to satisfy him.

I asked ChatGPT to write me a poem. And then I expressed my dissatisfaction with the poem and pointed out what I was disappointed by. ChatGPT then duly revised its poem to my satisfaction.


It revises the poem because it was RLHFed into an obedient “HHH” agent who knows the best policy for interacting with humans is to be obliging. So, like any obliging human, ChatGPT learns how best to satisfy me.
This is real learning, because the next time I ask the chatbot to write “a non-fiction piece on nature,” its writing is conditioned on the previous feedback I gave it. The chatbot recalls the feedback and incorporates it into the writing—kinda like how I would look at the essay feedback my English teacher gave me a long while ago to help me write my new essay.
This mode of in-session learning is unnerving. Because it is similar to how humans acquire high-level abstract knowledge for which we have no intuition.
Let me try to put this into perspective. Remember the first time you learned Linear Algebra (spoiler alert if you haven’t learned it)?
A vectorspace is a set V with scalar multiplication and a closed operator + such that the operations satisfy associativity, and distributive property, …
The point is, it wasn’t an intuitive concept. You didn’t learn vectorspace the same way you learned to speak English.
You learned to speak English by listening to your parents speak. Gradually, you start to make out the patterns of their speech and chunks of syllables (words) with meanings. In the process, you are rewiring your neural circuits—until listening and speaking English becomes second nature, something that requires no intellectual effort. The way we learned English corresponds to the way an LLM learns English—by looking through a large corpus and rewiring our neural networks (or in the case of an LLM, changing the weights in its neural network).
The way we learned vectorspaces, then, corresponds to an LLM’s in-session learning. Remember the linear algebra problems you did?
Prove the set of polynomials is or isn’t a vectorspace.
You read the problem. But your intuition was not able to provide an immediate answer. So, you reread the problem, and identified the keywords: “polynomial” and “vectorspace.” You recalled the definition of a “vectorspace”—the set of properties it must satisfy—and then you proceeded to check to see if the set of polynomials satisfied all those properties.
An LLM can learn linear algebra in-session too. If you put the definition of a vectorspace and a polynomial into your session history with an LLM, and you ask it to “prove the set of polynomials is or isn’t a vectorspace,” it can approach the problem in the same fashion as you and I would. The LLM would see the keyword “polynomial” and “vectorspace.” Its attention mechanism would allow it to search through its session history for the definition of these two jargons—just like how we can search through our memory to recall the definitions we need! Then, it mishmashes the two concepts together to generate the proof. If an LLM can answer questions drawing on abstract concepts you gave it during the session, I think we can conclude that it is capable of in-session learning!

The example of “polynomial” and “vectorspace” turned out to be bad examples. Because ChatGPT had probably read tons of Wikipedia articles on vectorspaces during its training. So, it already had the properties of vectorspaces wired into its neural network, allowing it to provide a swift answer based on its intuition. To show that the LLM could absorb abstract new knowledge during a session, I had to show it something it hadn’t seen before.
I defined a “new” operation “@” and asked it questions that would require an understanding of the operator to solve, and ChatGPT did a pretty good job! It absorbed the new “knowledge” of the “@” operator and applied that knowledge to solve problems.

I used small numbers (0, 1, 2) because ChatGPT is known to be bad at arithmetic. After ChatGPT correctly deduced the value of 1 @ 0, I then asked it a harder question.

It somehow copied the equation wrong during the computation, so I questioned its answer.

After that, it was able to correct its calculation mistake and give the right answer. Amazingly, just after correcting the LLM’s mistake once, it had “mastered” the “@” operator and produced correct answers to every following computation question I asked! It successfully grasped the algorithm for doing “@” calculations.
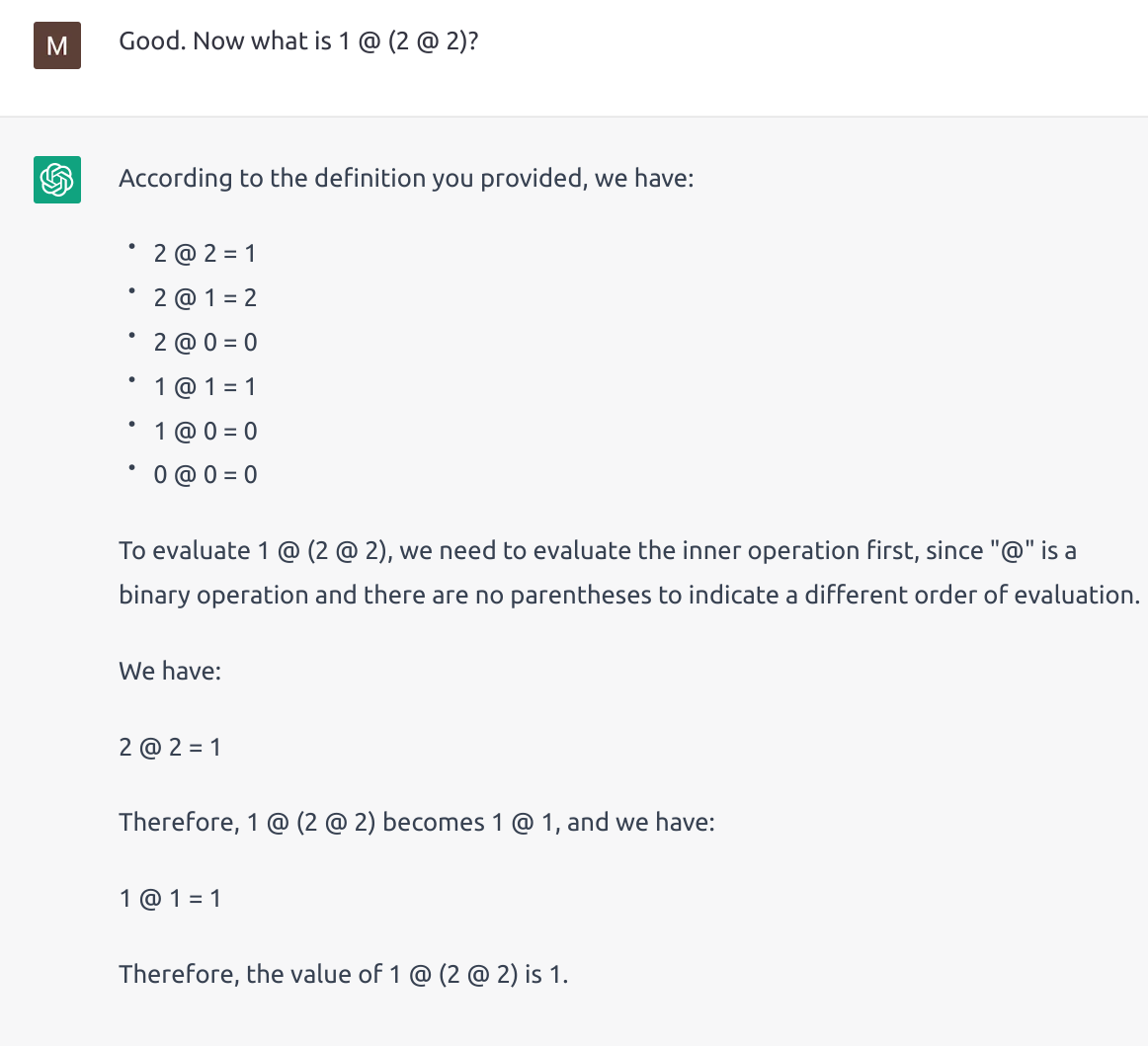

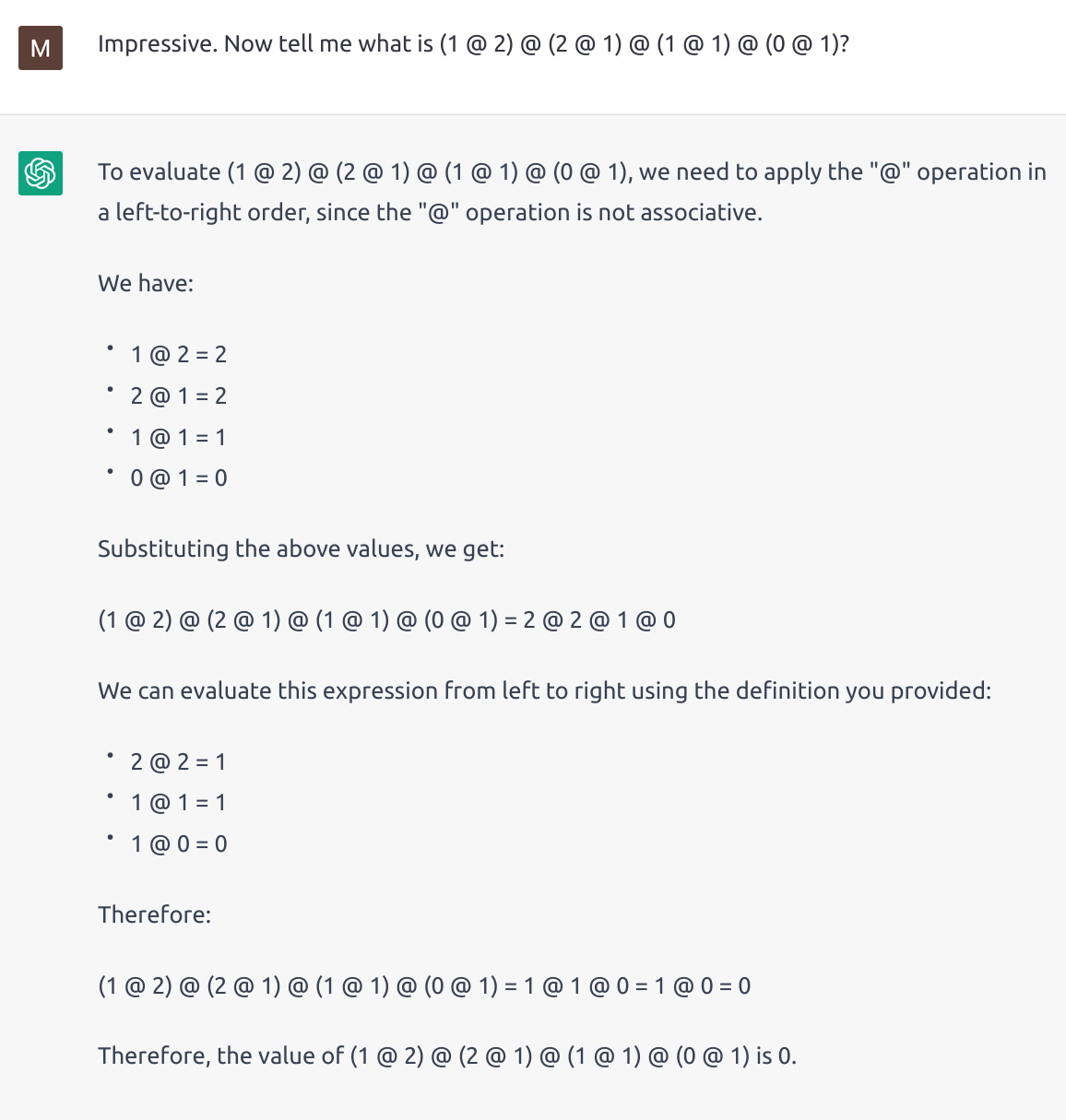
In-session learning is real learning and it functions similarly to how humans learn abstract concepts in the absence of intuition. Although there is no parameter tuning involved (rewiring of neural circuits), the session history itself serves as a memory bank for the LLM; its attention mechanism provides a way to recall the memory; and the intricate neural network inside the LLM allows it to do basic reasoning based on the information it “recalls” from the session history. The parallels between different components of an LLM’s in-session learning process and the human learning process suggest to me that LLMs can reach AGI through in-session learning. If an LLM’s session history (or I could call it, suggestively, “memory tape”) runs long enough, the LLM can accumulate knowledge (just like humans) over its session lifetime. It can also “practice” its logical reasoning ability over time, based on the human feedback we provide to it for each logical mistake it makes (the LLM can remember its logical mistakes and avoid the same fallacies next time).
How to make an AGI from LLMs
LLMs like ChatGPT and Bing are still far from AGI. I think there are several things we need to work on before they can reach human-level intelligence via in-session training.
Knowledge transfer from in-session training to “neural circuit”
We learn complicated things, like arithmetic, the same way a chatbot learns during its session. But over time, arithmetic crawls into our neural circuits and becomes our second nature. LLMs are not able to do that yet. LLMs can learn during its session. And it stores what it learns in the memory bank (session history). But to add this new knowledge to the LLMs’ intuition, we need some approach that allows us to connect the knowledge an LLM stores in its short-term memory bank to the parameters of its neural network.
Moving beyond feed-forward neural networks
Modern-day LLMs are built by stacking Transformer (attention mechanism) modules on top of each other. The lower layers deal with parsing English words and grammar while the higher layers deal with higher-level thinking (such as the logical relationship between different paragraphs in an essay). And information passes from the lower layers toward the higher layers. This is kinda different from how humans process complicated information. Say we are reading an essay. It is quite common for us to finish reading a paragraph (high-level processing) and then take a second look at one of its sentences (low-level processing) with the new context information we obtained. In other words, we don’t always go from low-level processing to high-level processing. Sometimes, we go in the reverse direction—using some high-level information to inform the comprehension a low-level sentence. LLMs don’t have this feature because it makes training the model with back-propagation difficult.
Linear processing with no reversibility
This is not a big issue. But I noticed that ChatGPT is very limited by the fact that it must spit out words one by one. When I ask it a “prove … is or is not …” question, it spits out the answer before going through the proof. ChatGPT thinks by writing. To reason through the question, it has to write all the reasoning down, step by step, because the neural network is not capable of making large logical jumps. Because ChatGPT provides an answer before writing out the proof, it is basically spitting out a guess before justifying its guess with a bunch of reasons. I want to point this out because people like to cite this on Twitter as evidence that GPT-3 is dumb. It’s not. It’s just simply not answering the question in the right logical sequence.
So, conclusions? LLMs can reach AGI by using in-session training, once we sort out some architectural kinks in Transformer models. That means AGI could be coming soon whether we like it or not.
I have often read psychologists claiming that language is an essential part of human thinking. Therefore, perhaps it is not surprising that language also offers machine a gateway to AGI.
But of course, I’m not Sam Altman, Gary Marcus, or Yann LeCun. So, take my takes with a grain of salt.